Batch Job Processing Model
The following is the basic type of batch job processing model.
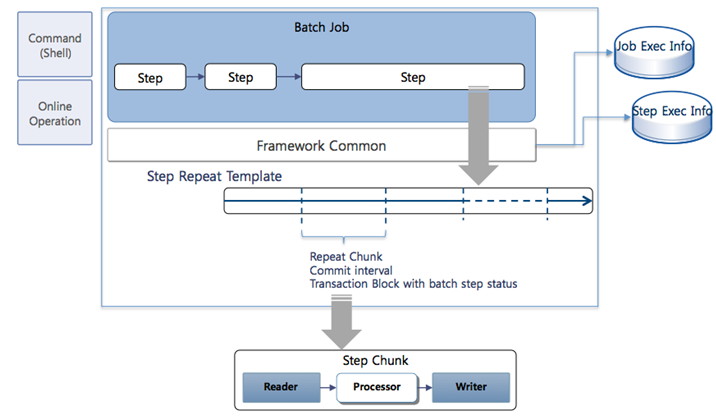
Figure 1. Basic Batch Job Processing Model
According to the above diagram, the batch job processing flow is as follows.
1. Start the batch job by using the execution command of the batch server (batch standard execution Shell) or by using an API from an online service.
2. Execute the flow of the batch job defined in the batch job XML (Job Configuration) in units of Steps.
3. The batch Step repeatedly processes until all input data is processed in "chunk" units using the commit-interval value of the Step (defined on the batch job management screen).
4. Use the ItemReader and ItemProcessor defined in the Step to read the data, convert it into items, and then process them.
5. Deliver the processed items to the ItemWriter in "chunk" units to write them to files or persist them to databases.
6. Record the processing status (read, write, commit count, etc.) of the batch job and individual Steps in an aggregate table.
7. Monitor the progress using the recorded aggregate data and the web admin, or perform reprocessing according to the execution result.