새로운 배치 작업
새로운 배치 작업 마법사의 기능에 대해 설명합니다.
배치 Job 유형(chunked, tasklet), 배치의 Reader/Writer 유형(File, DB 등)에 따라 자동으로 배치 Bean, DBIO, Job Config 파일을 생성해주는 기능입니다.
배치 Job 유형은 크게 두 가지가 있습니다.
| 배치 Job 유형 | 설명 |
|---|---|
Tasklet |
단순 DB CRUD 수행이나 반드시 한 번에 commit/rollback되어야 하는 배치에 사용합니다. |
Chunked |
DB 또는 파일로부터 한 건 단위로 입력받은 |
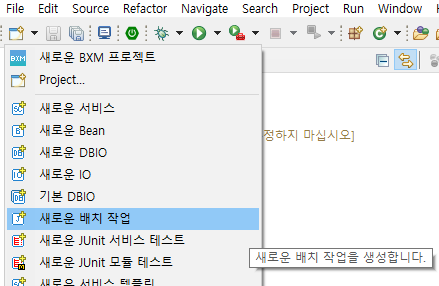
새로운 배치 작업 마법사는 아래 그림과 같이 실행합니다.
-
좌측 상단 퀵 메뉴 New → '새로운 배치 작업' 을 클릭합니다.
1. Tasklet
단순 DB CRUD 수행이나 반드시 한 번에 commit/rollback되어야 하는 배치에서 사용됩니다.
-
Tasklet 유형 선택 및 작업 아이디를 입력하고 Next를 클릭합니다.
이 때 스텝 아이디와 쉘 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
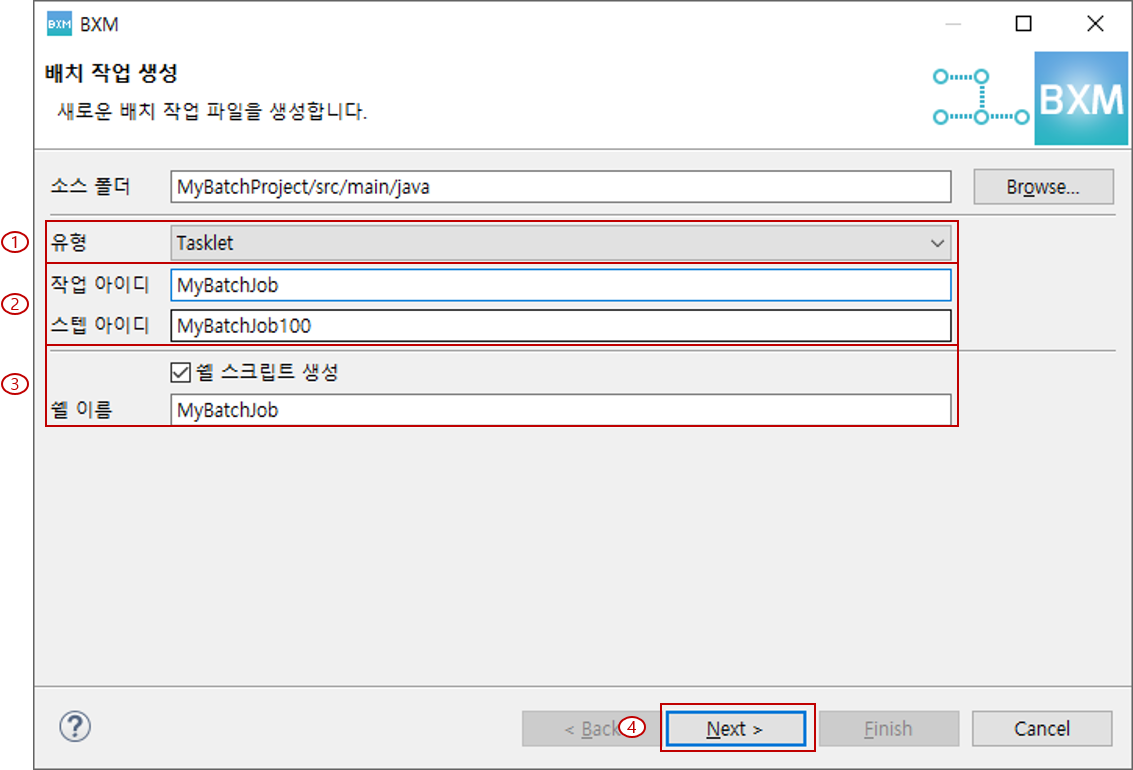
(1) Tasklet 유형 선택
(2) 작업 아이디, 스텝 아이디 입력
(3) 쉘 스크립트 생성 사용 여부 및 쉘 이름 입력
(4) Next 클릭 -
패키지, 타입, 논리 이름을 입력합니다.
이 때 패키지, 타입, 논리 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
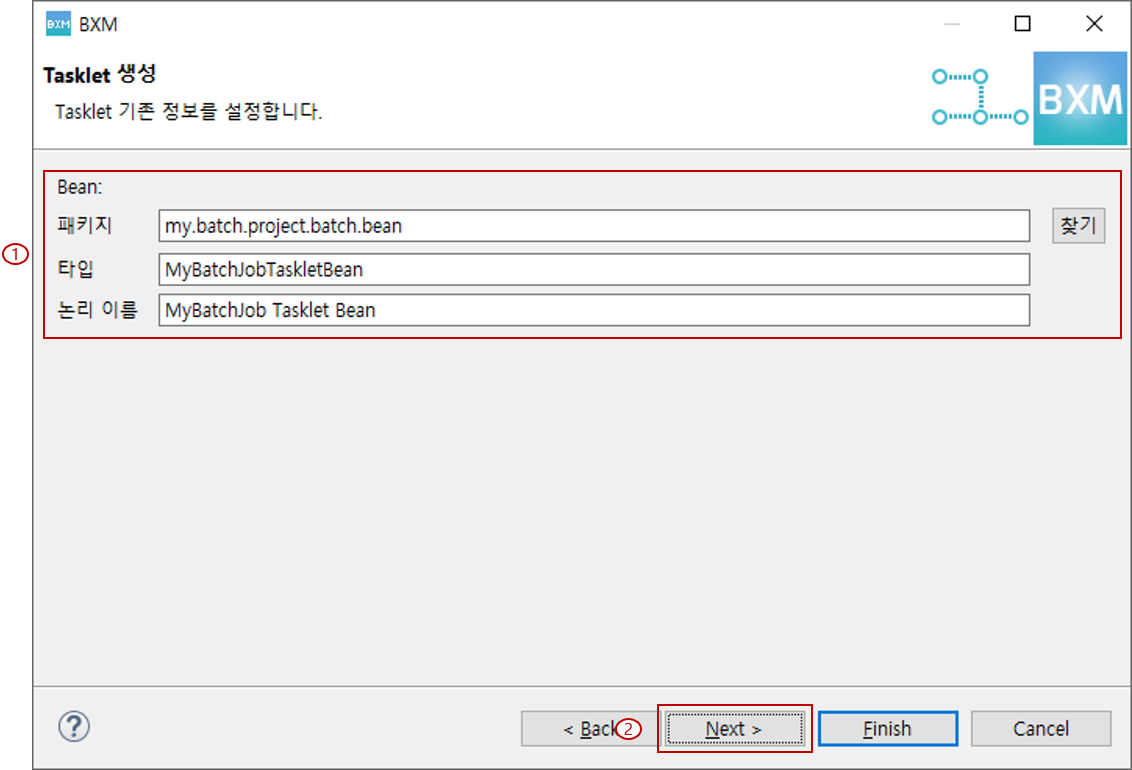
(1) 패키지, 타입, 논리 이름을 입력
(2) Next 클릭
2. Chunk
DB 또는 파일로부터 한 건 단위로 입력받은 ItemReader 와 한 건 단위로 비즈니스 로직을 처리하는 ItemProcessor, 결과를 출력하는 ItemWriter 를 정의하여 사용합니다.
-
Chunked 유형 선택 및 작업 아이디를 입력하고 Next를 클릭합니다.
이 때 스텝 아이디와 쉘 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
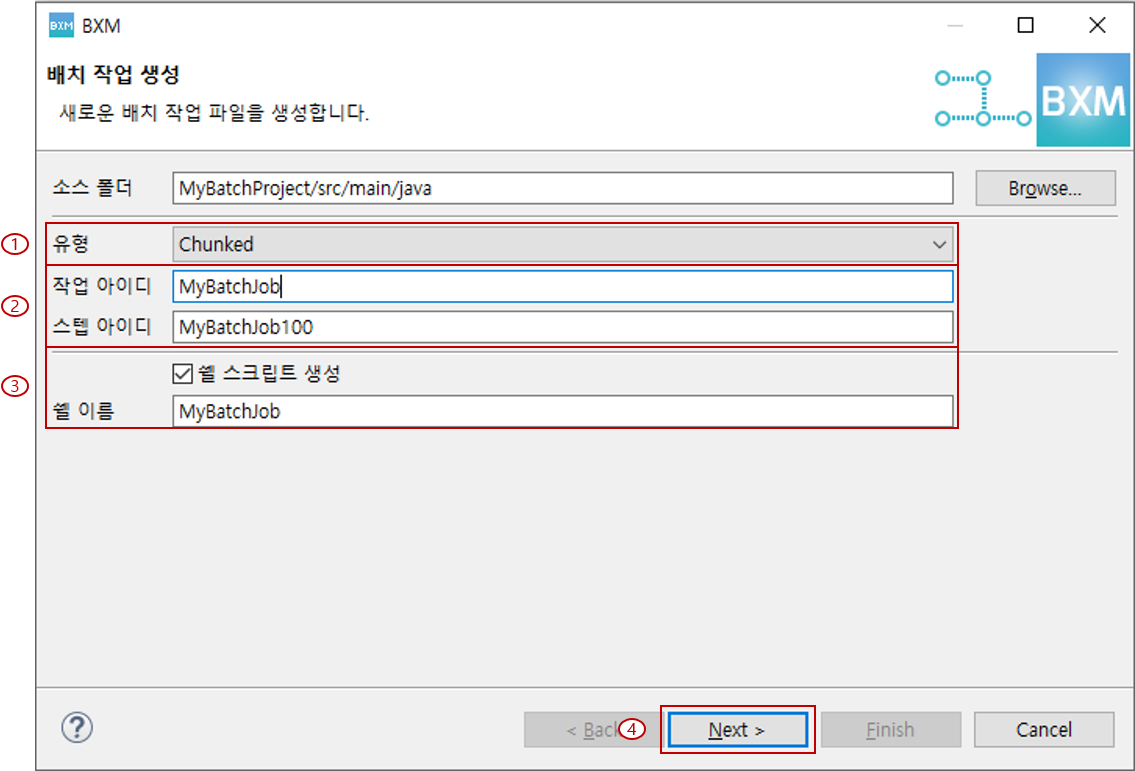
(1) Chunked 유형 선택
(2) 작업 아이디, 스텝 아이디 입력
(3) 쉘 스크립트 생성 사용 여부 및 쉘 이름 입력
(4) Next 클릭 -
Reader의 타입, 입력 패키지, 타입, 논리 이름,Processor의 사용 여부,Writer의 사용 여부, 타입, 출력 패키지, 타입, 논리 이름, 데이터 소스를 선택하고 Next를 클릭합니다.이 때 패키지, 타입, 논리 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
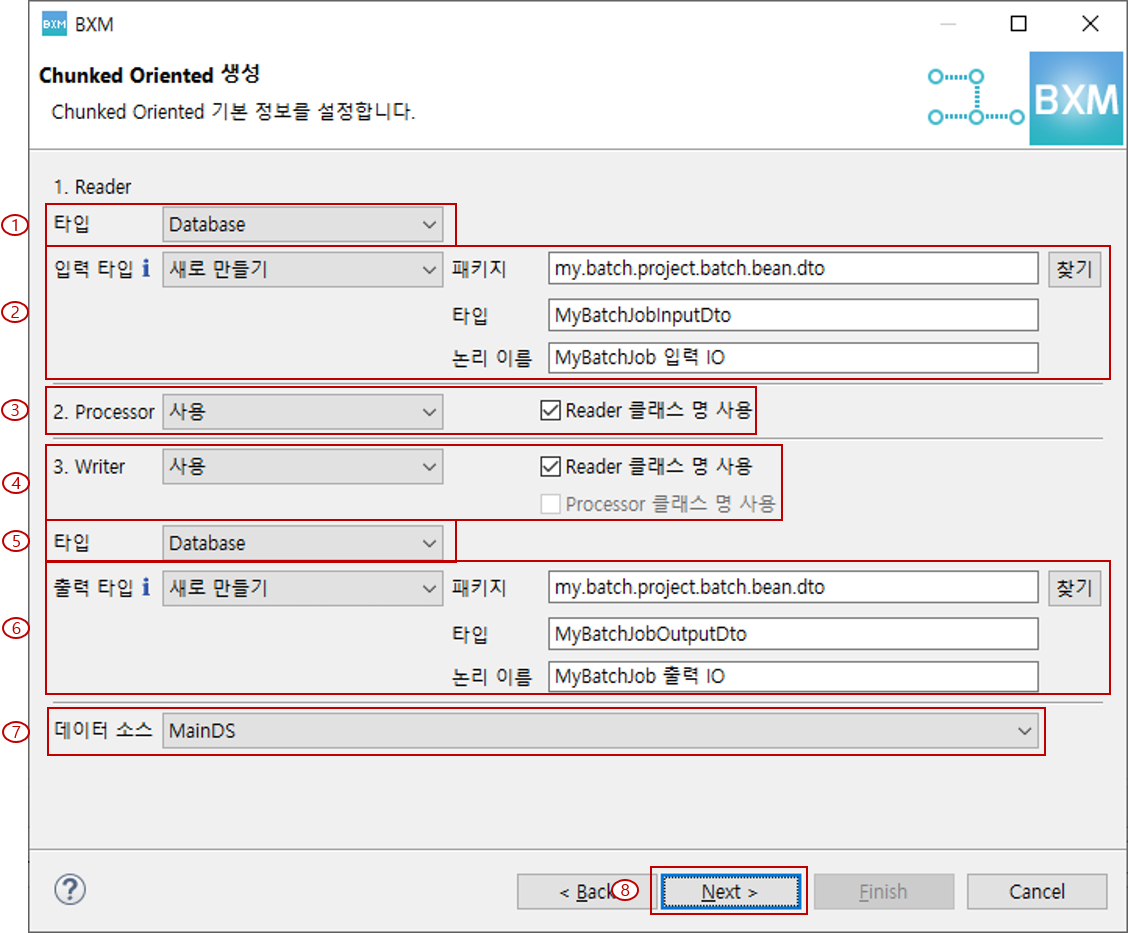
(1)
Reader타입 선택Reader 유형 설명 Database
DBIO를 이용하여 배치 처리 대상 데이터를 조회할 경우 사용합니다.
Fixed
고정(Fixed)된 길이의 파일을 Read할 경우 사용합니다.
Delimited
구분 값(Delimiter)으로 정의되어진 파일을 Read할 경우 사용합니다.
MultiType Fixed
고정(Fixed)된 길이로 Header/Body/Footer 구조를 가진 파일을 Read할 경우 사용합니다.
MultiType Delimited
구분 값(Delimiter)으로 Header/Body/Footer 구조로 되어진 파일을 Read할 경우 사용합니다.
Variable
문자열 형태로 1라인씩 파일을 Read할 경우 사용합니다.(
String으로ItemProcessor에 전달하기 때문에 IO를 정의하지 않습니다.)File Read Source(Fixed)
고정(Fixed)된 길이의 파일을 소스코드로 작성하여 Read할 경우 사용합니다.
File Read Source(Delimited)
구분 값(Delimiter)으로 정의되어진 파일을 소스코드로 작성하여 Read할 경우 사용합니다.
(2) 입력 타입 패키지, 타입, 논리 이름 입력
(3)Processor사용 여부 및 옵션 선택
(4)Writer사용 여부 및 타입 선택Writer 유형 설명 Database
DBIO를 이용하여 결과 데이터를 추가/수정/삭제할 경우 사용합니다.
Fixed
고정(Fixed)된 길이의 파일을 Write할 경우 사용합니다.
Delimited
구분 값(Delimiter)으로 정의되어진 파일을 Write할 경우 사용합니다.
MultiType Fixed
고정(Fixed)된 길이로 Header/Body/Footer 구조를 가진 파일을 Write할 경우 사용합니다.
MultiType Delimited
구분 값(Delimiter)으로 Header/Body/Footer 구조로 되어진 파일을 Write할 경우 사용합니다.
Variable
문자열 형태로 1라인씩 파일을 Write할 경우 사용합니다.
File Read Source(Fixed)
고정(Fixed)된 길이의 파일을 소스코드로 작성하여 Write할 경우 사용합니다.
File Read Source(Delimited)
구분 값(Delimiter)으로 정의되어진 파일을 소스코드로 작성하여 Write할 경우 사용합니다.
(5) 출력 타입 패키지, 타입, 논리 이름 입력
(6) 데이터 소스 선택
(7) Next 클릭
2.1. Reader 유형 별 정의
Reader 유형 별로 필요한 정보를 기입합니다.
2.1.1. Database 유형
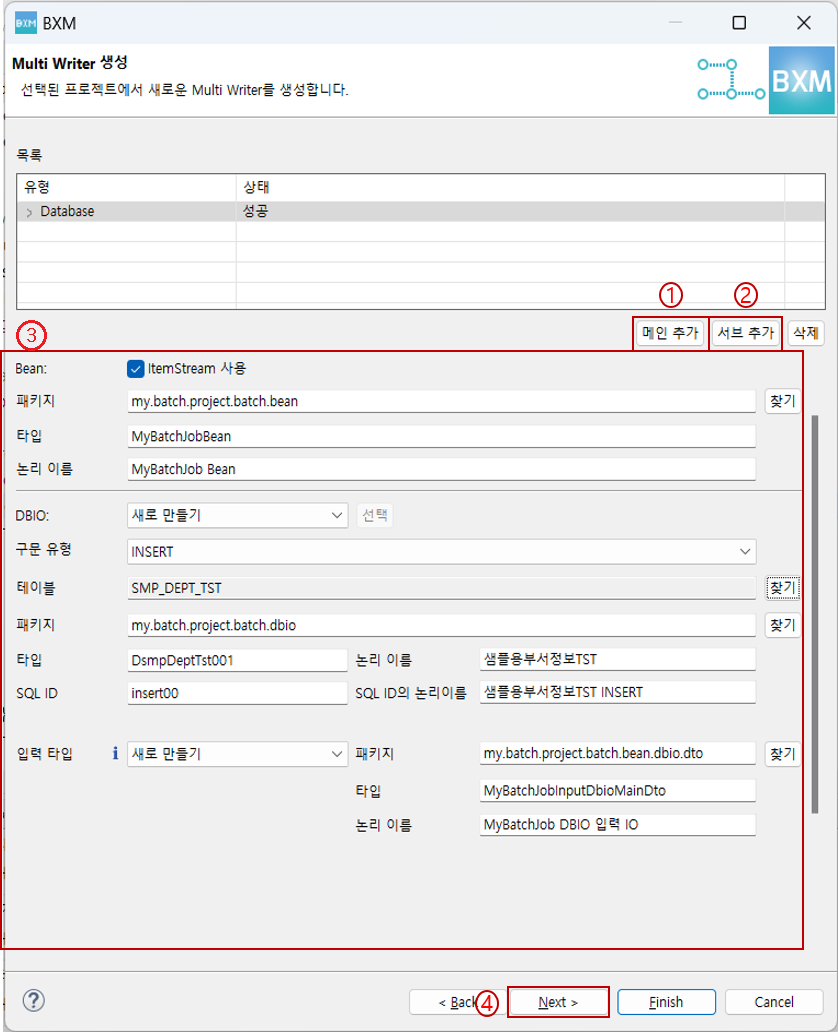
-
Bean 패키지, 타입, 논리 이름 및 구문 유형, 원하는 테이블을 선택한 후, Next를 클릭합니다.
이 때 모든 자원의 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
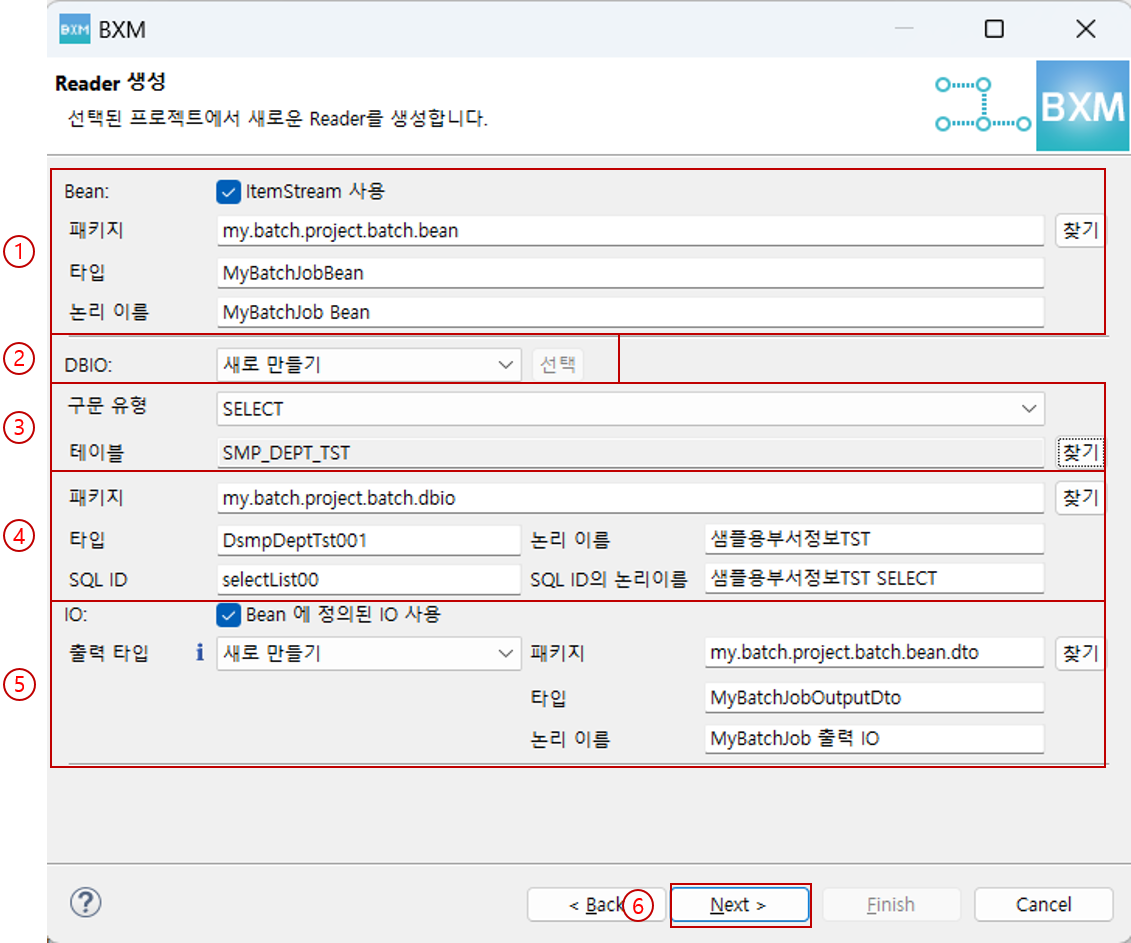
(1) Bean의 패키지, 타입, 논리 이름을 입력
(2) DBIO 생성 방식 선택 (새로 만들기, 기존 DBIO 선택)
(3) 구문 유형 및 테이블 선택
(4) DBIO 패키지, 타입, 논리 이름, SQL ID, SQL ID의 논리이름 입력
(5) 출력 타입 패키지, 타입, 논리 이름 입력
(6) Next 클릭
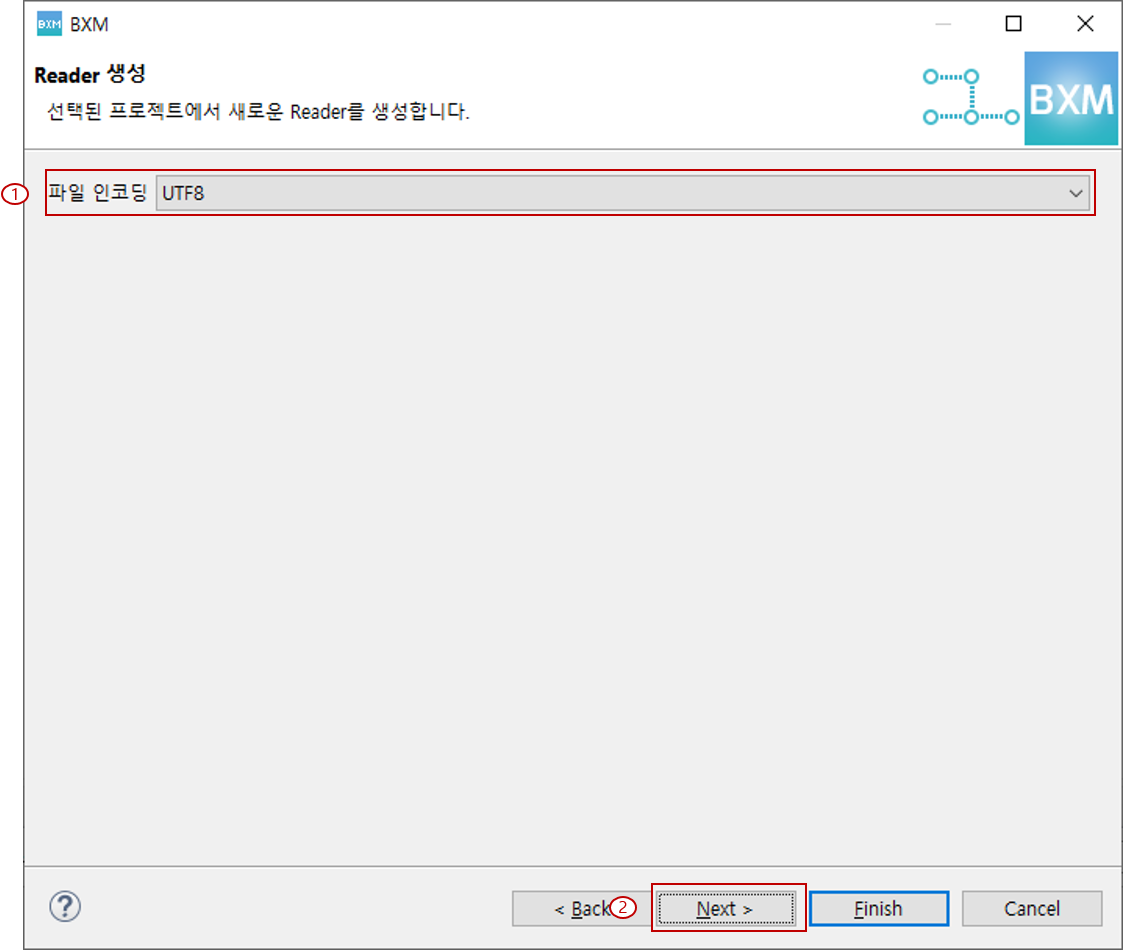
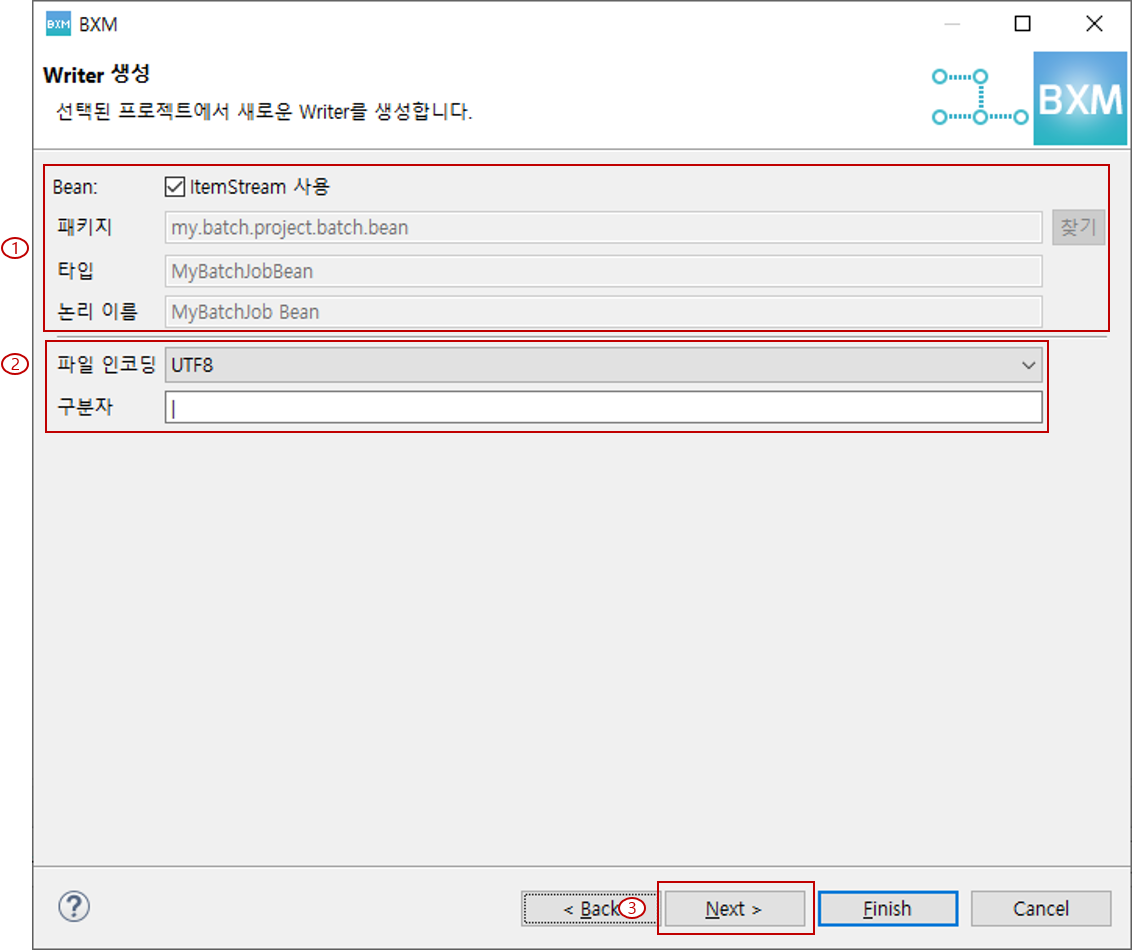
2.1.3. Delimited, MultiType Delimited 유형
-
파일 인코딩 선택 및 구분자 입력 후, Next를 클릭합니다.
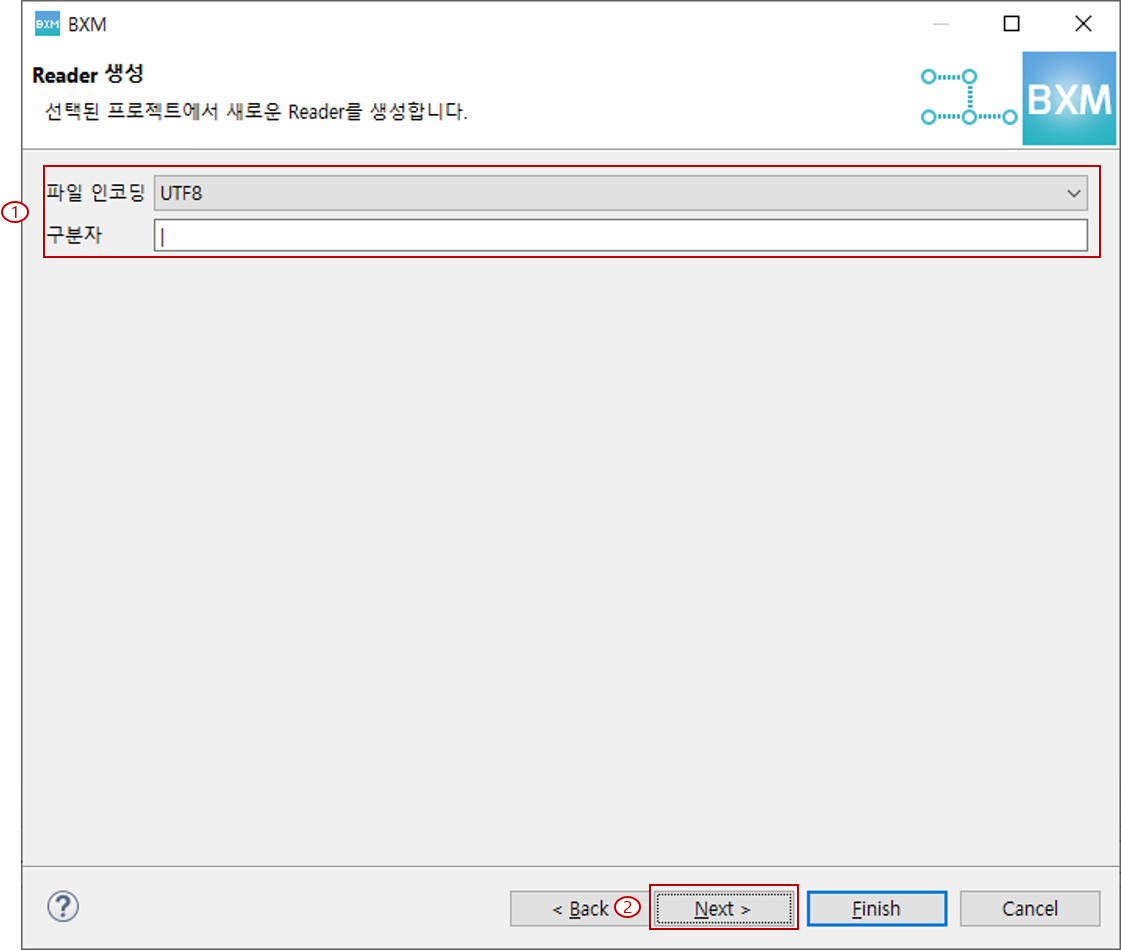
(1) 파일 인코딩 선택 및 구분자 입력
(2) Next 클릭
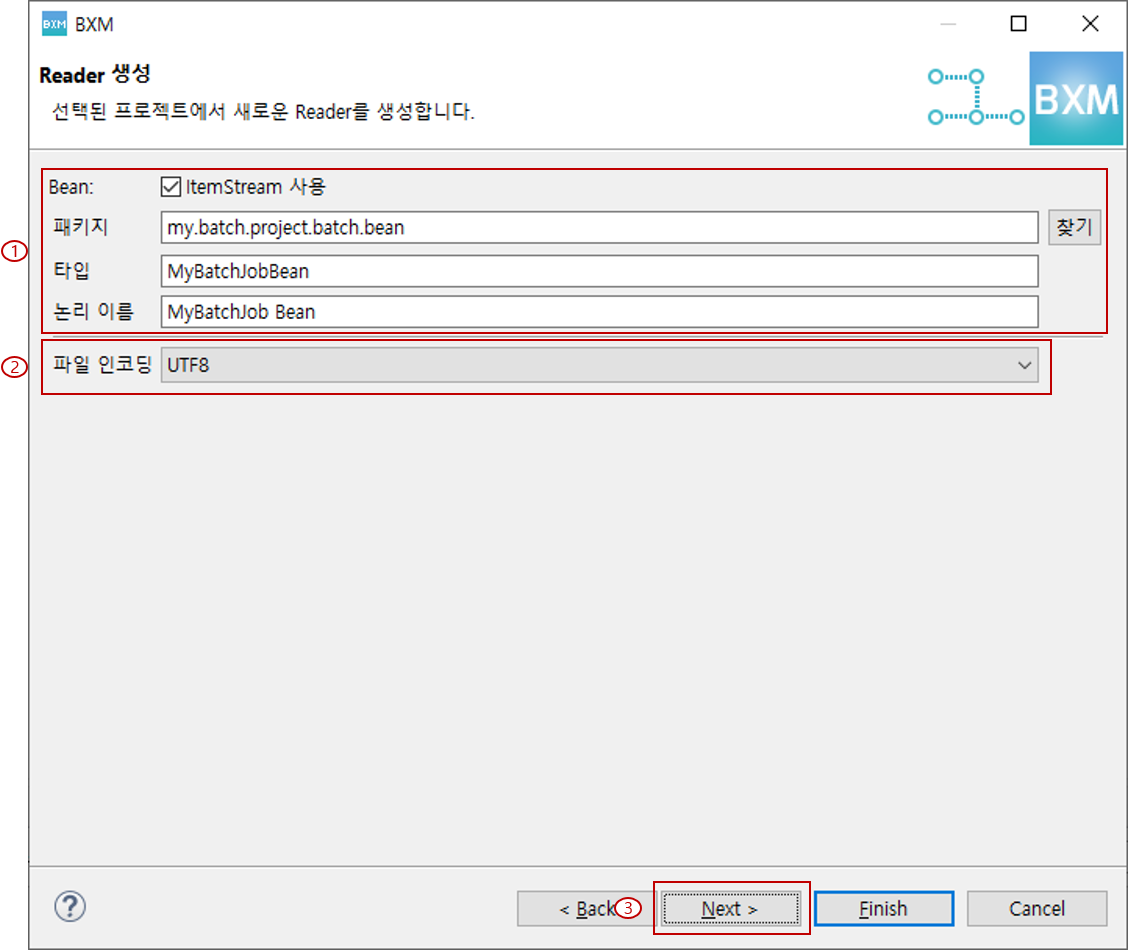
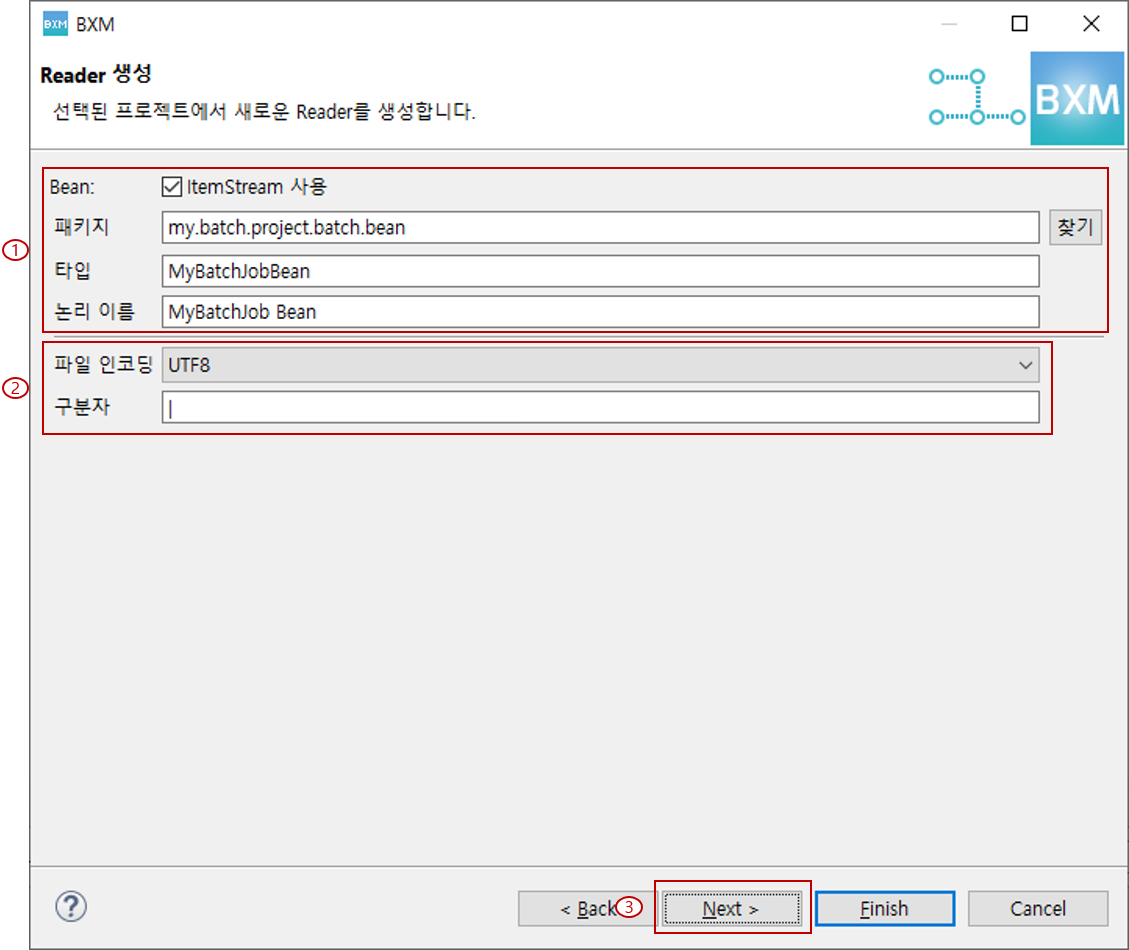
2.2. Processor 정의
Processor Bean의 필요한 정보를 기입합니다.
-
Bean의 패키지, 타입, 논리 이름 입력 후, Next를 클릭합니다.
이 때 모든 자원의 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다. 또한 유형 선택 페이지에서 Reader 클래스 명 사용 체크 시 해당 페이지는 스킵됩니다.
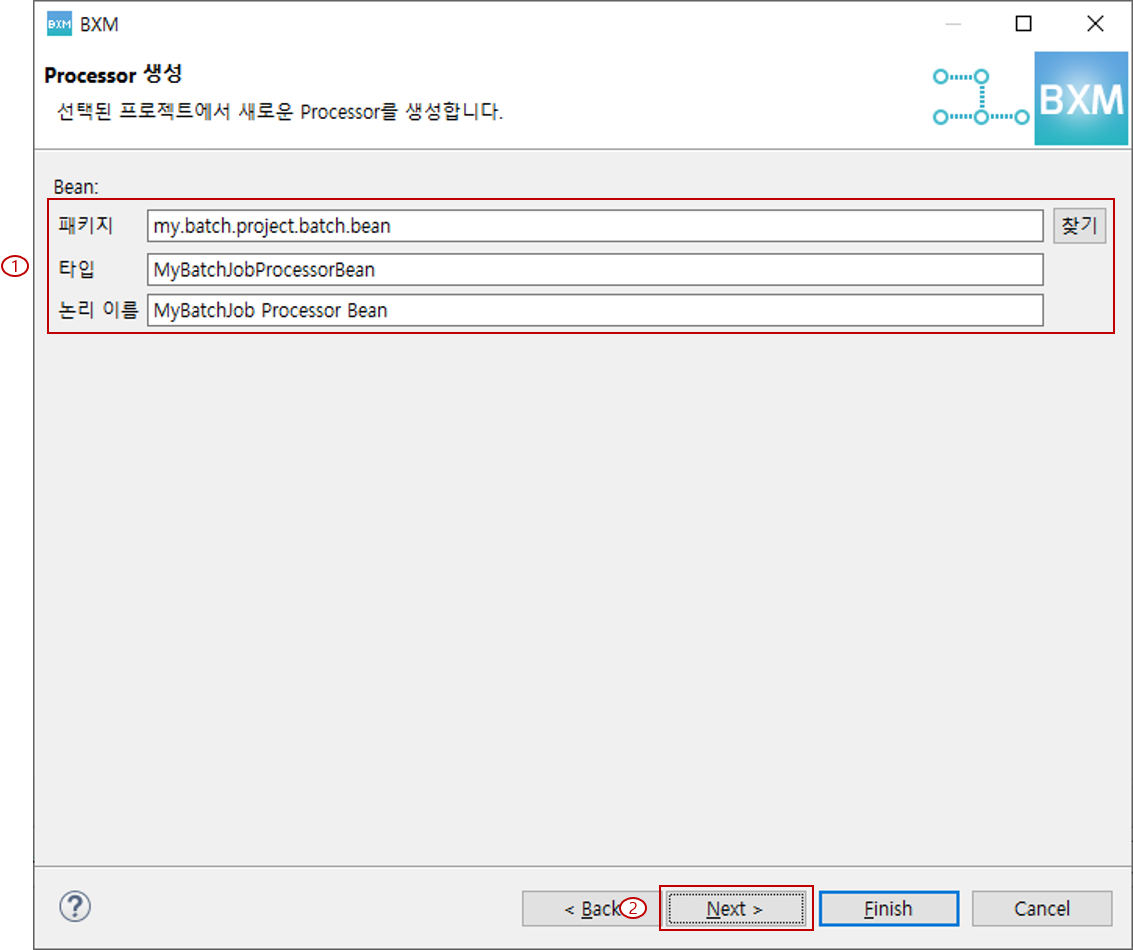
(1) Bean의 패키지, 타입, 논리 이름 입력
(2) Next 클릭
2.3. Writer 유형 별 정의
Writer 유형 별로 필요한 정보를 기입합니다.
2.3.1. Database 유형
-
Bean 패키지, 타입, 논리 이름 및 구문 유형, 원하는 테이블을 선택한 후, Next를 클릭합니다.
이 때 모든 자원의 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
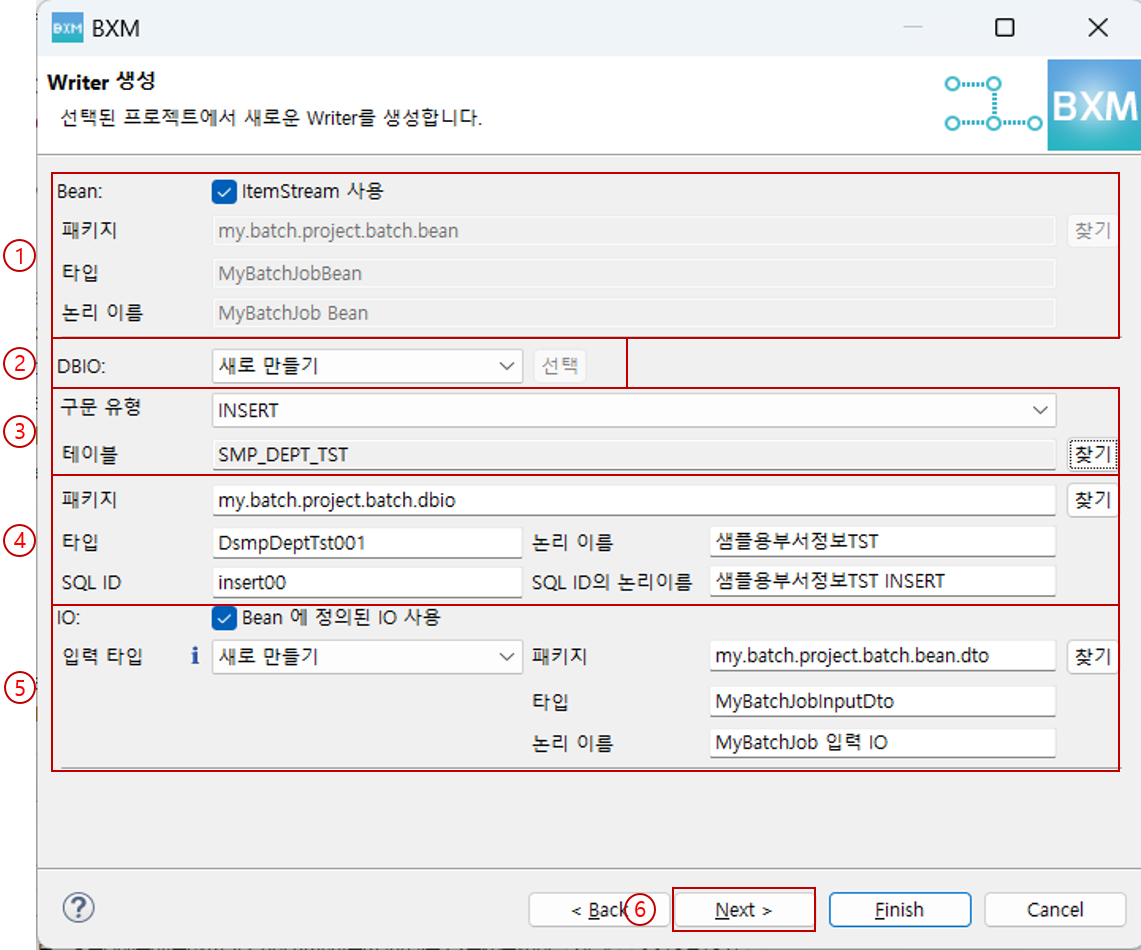
(1) Bean의 패키지, 타입, 논리 이름을 입력
(2) DBIO 생성 방식 선택 (새로 만들기, 기존 DBIO 선택)
(3) 구문 유형 및 테이블 선택
(4) DBIO 패키지, 타입, 논리 이름, SQL ID, SQL ID의 논리이름 입력
(5) 출력 타입 패키지, 타입, 논리 이름 입력
(6) Next 클릭
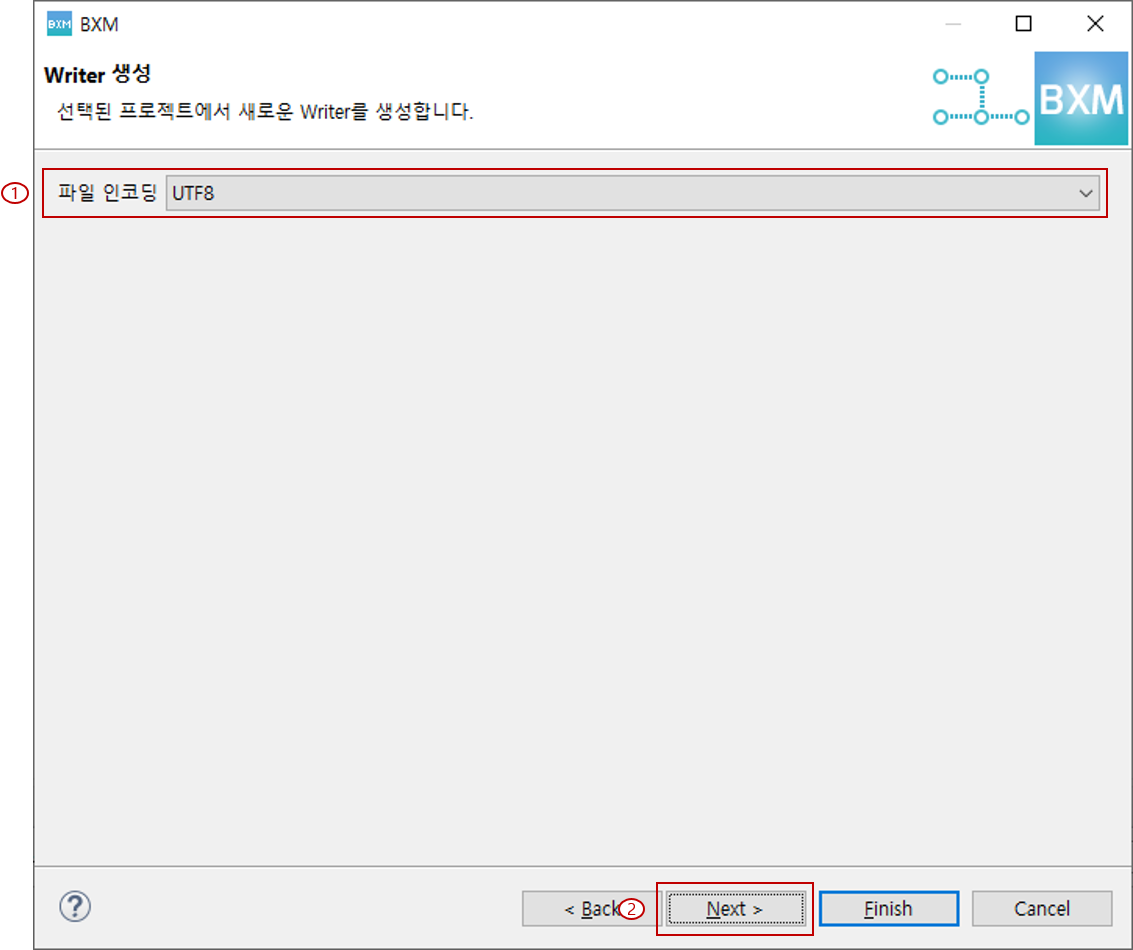
2.3.3. Delimited, MultiType Delimited 유형
-
파일 인코딩 선택 및 구분자 입력 후, Next를 클릭합니다.
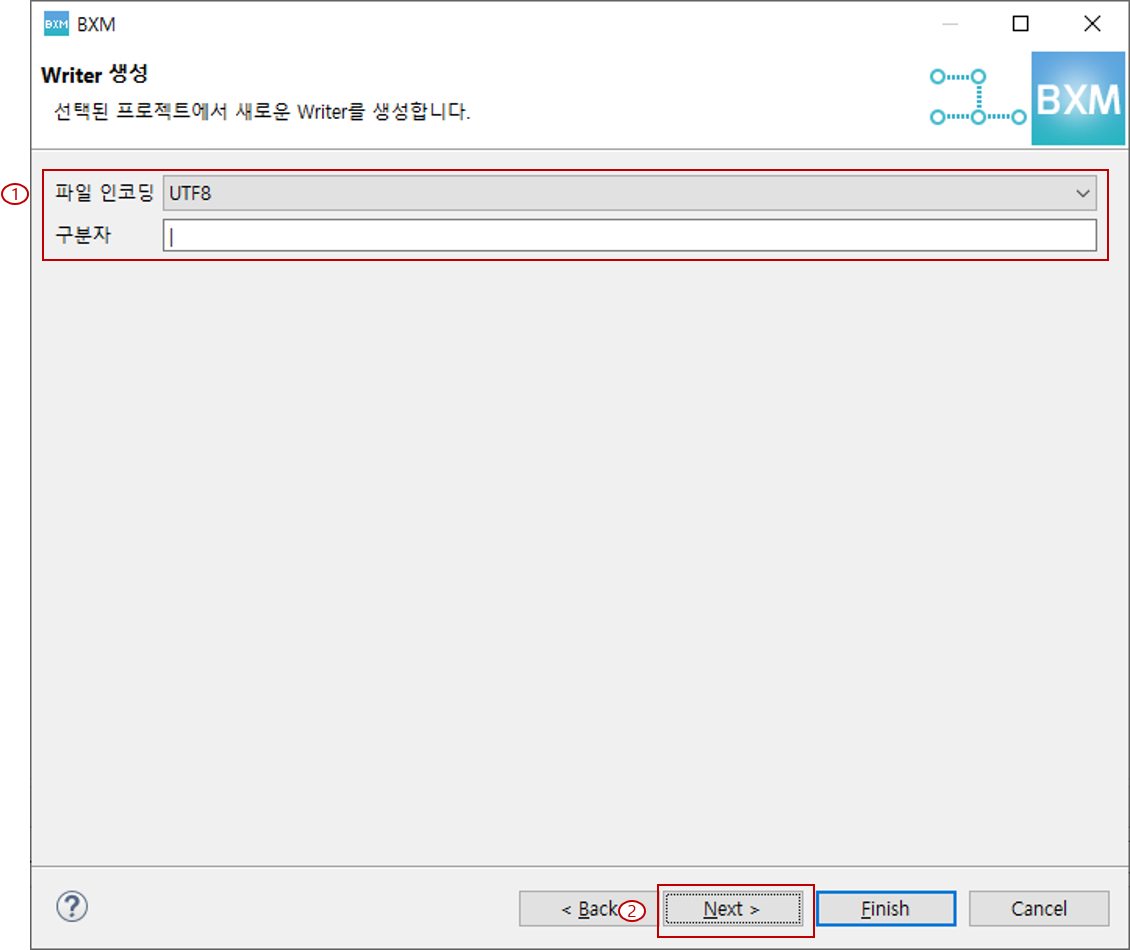
(1) 파일 인코딩 선택 및 구분자 입력
(2) Next 클릭
2.3.4. File Write Source(Fixed) 유형
-
Bean의 패키지, 타입, 논리 이름 입력 및 파일 인코딩 선택 후, Next를 클릭합니다.
이 때 모든 자원의 이름은 프레임워크 담당자가 정의한 모듈에 의해 자동 완성됩니다.
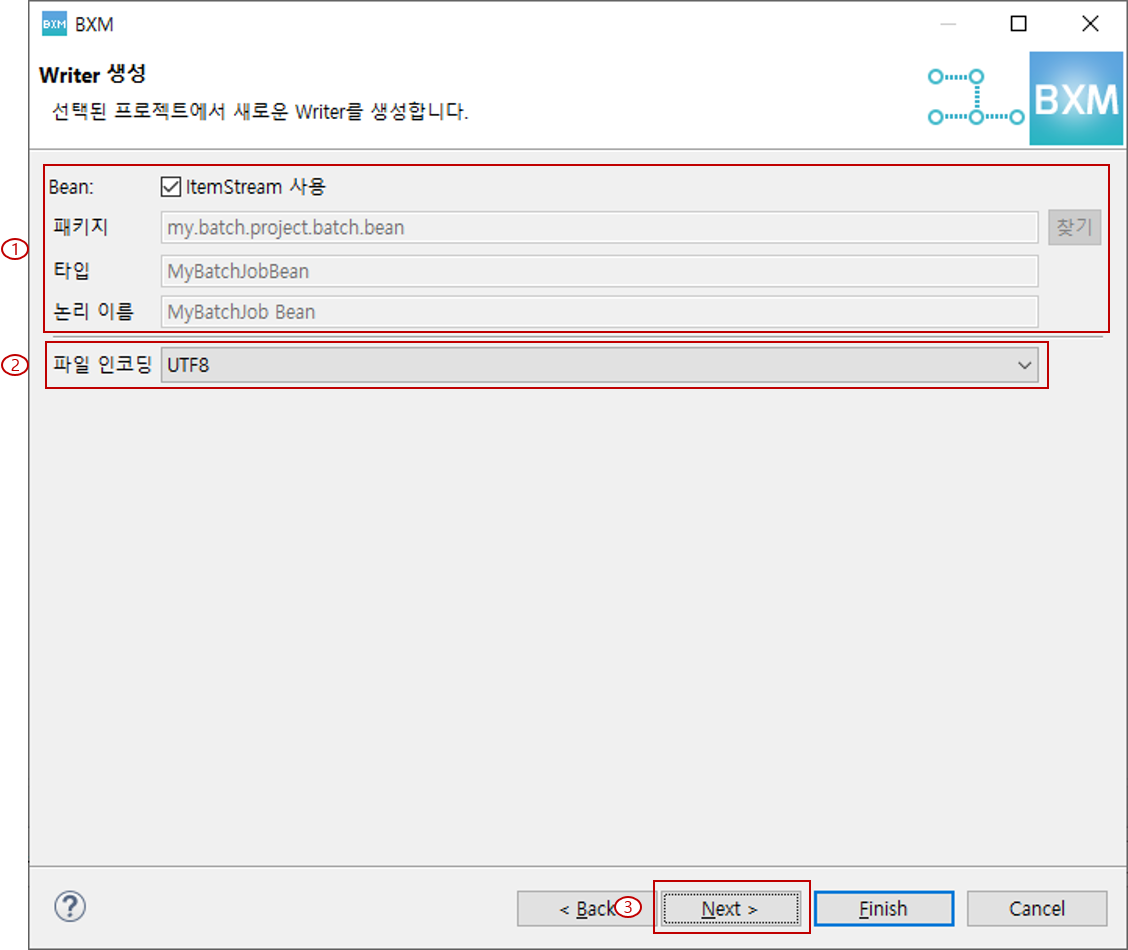
(1) Bean의 패키지, 타입, 논리 이름 입력
(2) 인코딩 선택
(3) Next 클릭