후행 흐름
아래의 그림은 후행이 어떠한 흐름인지 나타내는 그림이다.
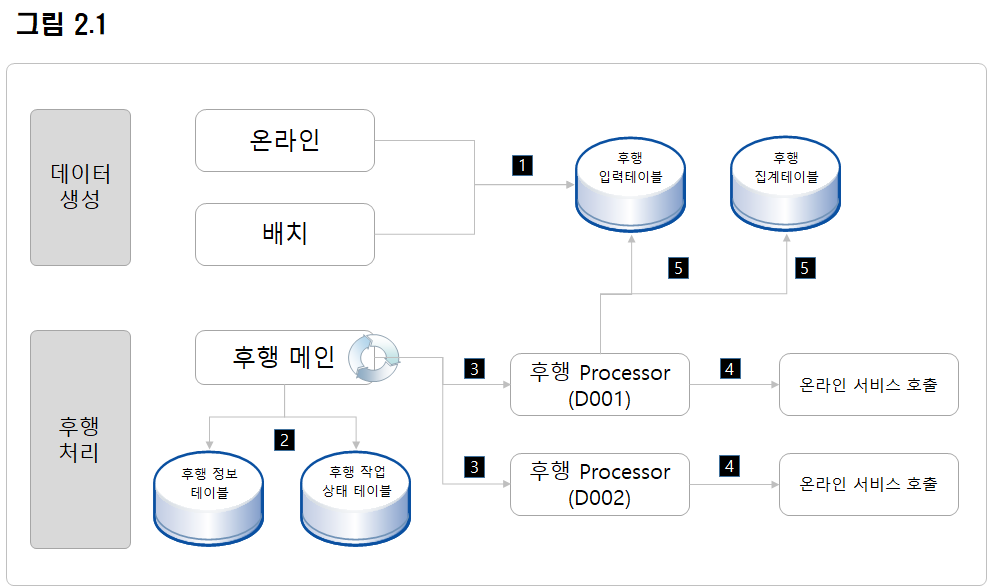
1. 후행 흐름 설명
후행 흐름은 다음과 같다.
-
후행 입력 데이터 생성
-
온라인, 배치 에서 후행 입력 데이터 적재 API 를 사용하여 입력 데이터를 적재 한다.
-
API 입력 아규먼트는 후행 ID, 입력 데이터 등 으로 구성 된다.
-
-
후행 입력 데이터 조회
-
후행 메인에서 후행 정보 테이블, 후행 작업 상태 테이블, 후행 허용 노드 테이블, 후행 입력 데이터 테이블을 조인하여 입력데이터를 가져온다.
-
조회해 해오는 fetchCount 는 bxm.deferred.fetch.count properties 설정을 따른다. 기본 값은 20이다.
-
조회하는 내부 상세 동작은 다음과 같다.
-
입력 데이터를 조회할 때, 등록 일시 순으로 정렬한 후, fetchCount 만큼 조회를 한다.
-
조회한 입력 데이터에 대해 읽어온 것을 다른 후행 인스턴스에 알려주기 위해 마킹을 하게 된다. (미완료 -→ 진행 중)
-
이 때, 마킹하는 과정에서 조회한 입력 데이터 갯수와 마킹해서 업데이트 된 rows 가 틀릴 경우 마킹 작업은 롤백된다.
-
이는 동시에 여러 개의 후행 인스턴스가 같은 데이터를 가져왔을 때, 충돌이 나는 경우를 막기 위함이다.
-
또한, 마킹하는 과정에 있어서 ORACLE 의 경우 트랜잭션 레벨이 COMMITED READ 이기에 문제가 안되지만, 다른 DBMS 의 경우 COMMITED READ 보다 윗단계의 트랜잭션 레벨인지 확인이 필요하다.
-
-
-
후행 메인에서 각 후행 프로세서 호출
-
후행 메인은 조회해온 후행 입력 데이터를 loop 문을 수행하여, 후행 프로세서를 호출 한다. 이 때, 후행 입력 데이터를 sorting 하여 후행 ID 별로 Processor 를 호출 한다.
-
2, 3번의 과정은 주기적으로 (3 ~ 4초) 후행 메인에 의해 수행 된다
-
-
후행 프로세서에서 온라인 서비스 호출
-
후행 프로세서는 입력받은 데이터를 for 문을 수행하여, 건 별로 온라인 서비스를 호출한다. 이 때, 트랜잭션 단위는 건 별로 수행된다.
-
-
후행 작업 수행 결과 반영
-
건 별로 정상적으로 완료됐다면, 후행 입력 테이블과 후행 집계 테이블에 정상 처리 결과를 반영 한다.
-
처리 도중 온라인 서비스에서 에러가 발생하였다면, 후행 작업 정보에 따라 Retry 를 하거나 에러 결과를 입력 테이블과 집계 테이블에 반영 한다.
-
입력받은 데이터를 전부 처리하면 해당 프로세서는 종료한다.
-