배치작업 병렬 처리
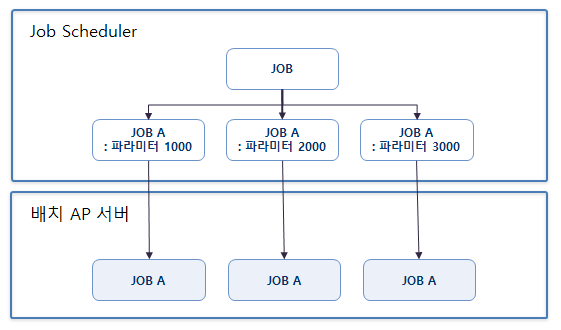
배치의 병렬처리는 스케줄러에서 동일한 배치 Job을 서로 다른 파라미터 값으로 호출하는 Job 병렬처리와 하나의 배치 Job 내에서 여러 개의 Step을 동시에 수행하는 Step 병렬 처리하는 방법이 있다.
1. 배치 Job 병렬 처리
스케줄러에서 동일한 Job을 서로 다른 파라미터 값으로 동시에 호출 처리하는 방법이다.
프레임워크에서는 배치 Job ID와 실행 파라미터(JobParameter)의 조합으로 Job Instance를 생성하여 동일한 배치 Job이 여러 개 실행 되도록 한다.
2. 하나의 배치 병렬Job 내에서 Step 병렬 처리
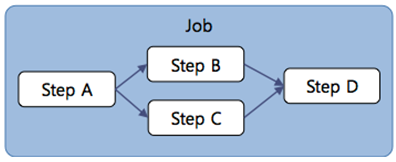
일부 단위 Step들을 순서와 상관없이 동시에 처리되도록 Step 플로우를 정의하여 병렬로 처리할 수 있다.
('4장. Step 실행 플로우' 참조)
3. 데이터 Partition 처리
처리 데이터를 분할하여 동시에 여러 쓰레드가 분할된 데이터를 병렬로 처리하하는 방법이다.
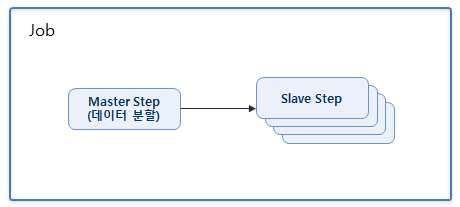
배치 작업 xml에서는 Master Step은 partition 요소로 정의 되어야 하며 Slave Step은 Job 흐름도 밖에 위치하여 한다.
handler 요소의 grid-size 속성 값으로 병렬처리 할 개수를 설정한다. 이 개수 값은 Partitioner 클래스의 partition 메소드의 파라미터로 전달된다.
<job id="JSmpPartitioning" xmlns="http://www.bankwareglobal.com/schema/batchex">
<step id="JSmpPartitioning100" parent="parentStep">
<partition partitioner="MSmpPartitioning" step="JSmpPartitioning200">
<handler grid-size="3"/>
</partition>
</step>
</job>
<step id="JSmpPartitioning200" parent="parentStep" xmlns="http://www.bankwareglobal.com/schema/batchex">
<tasklet>
<chunk reader="MSmpPartitioningDBToFixedBtch" processor="MSmpPartitioningDBToFixedBtch" writer="WJSmpPartitioning200"/>
</tasklet>
</step>Partitioner 클래스 : 분할 대상 데이터 확인 및 분배 로직을 구현한다.
(ExecutionContext를 이용해서 다음 Step에 분할 처리할 데이터를 전달한다.)
@BxmBean("MSmpPartitioning")
@Scope("step")
@BxmCategory(logicalName = "MSmpPartitioning")
public class MSmpPartitioning implements Partitioner{
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Override
@BxmCategory(logicalName = "MSmpPartitioning")
public Map<String, ExecutionContext> partition(int gridSize)
{
/**
* Partition으로 분배한 Step의 ExecutionContext 정보를 전달하기 위한 Map
* - Map의 Size 만큼 병렬로 Step이 수행이 된다. (보통 전달받은 gridSize 값이 Map의 size로 정의된다.)
*/
Map<String, ExecutionContext> executionContextMap = new HashMap<String, ExecutionContext>();
/**
* gridSize 만큼 ExecutionContext Map에 설정한다.
*/
for(int ix = 1; ix <= gridSize; ix++)
{
/**
* ExecutionContext 값 설정
* - Partitioning으로 수행할 값을 설정처리하면 된다.
*/
ExecutionContext executionContext = new ExecutionContext();
executionContext.put("deptNo", ix * 10);
/**
* Partition Id를 key로 ExecutionContext값을 설정한다.
*/
executionContextMap.put("id_" + ix, executionContext);
}
return executionContextMap;
}
}Slave Step에서는 전달 받은 ExecutionContext에서 대상범위를 확인한다.
@BxmCategory(logicalName = "open : 샘플용 직원정보 Iterator 처리")
public void open(ExecutionContext executionContext) throws ItemStreamException
{
if(dSmpEmpTst001 == null) {
dSmpEmpTst001 = DefaultApplicationContext.getBean(DSmpEmpTst001.class);
}
/**
* 배치 입력파라미터 "deptNo" Get
*/
int deptNo = executionContext.getInt("deptNo");
/**
* 입력받은 "deptNo" 에 대하여 샘플용 직원정보를 Iterator로 가져온다.
*/
DSmpEmpTst001selectList01InDto inDto = new DSmpEmpTst001selectList01InDto();
inDto.setFeduDeptNo(deptNo);
iterator = dSmpEmpTst001.selectList01(inDto).iterator();
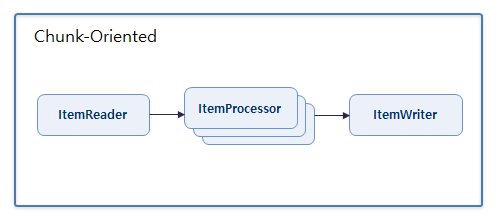
}4. ItemProcessor 병렬 처리
ItemReader와 ItemWriter는 동기로 ItemProcessor만 비동기 병렬로 처리하는 방법이다.
※ 주의 병렬처리되는 ItemProcessor에서 사용하는 멤버면수에 대해서는 Thread Safe한 타입(AtomicInteger, AtomicReference .. 등)을 사용애야 함을 주의행 한다. 또한 병렬로 처리되는 ItemProcessor의 Select 처리는 빠른 처리 속도를 위하여 별도의 Connection을 사용하므로 라애와 같은 경우 정상적으로 수행되지 않을 수 있다.
-
FOR UPDATE 를 사용한 경우(Oracle)
-
ItemProcessor 내에서 C/U/D 처리한 데이터를 재 조회한 경우
<job id="JSmpAsynItemProcessor" xmlns="http://www.bankwareglobal.com/schema/batchex">
<step id="JSmpAsynItemProcessor100" parent="parentStep">
<tasklet tm-datasource="MainDS">
<chunk reader="MSmpTestChunkedBean" processor="AsyncMSmpTestChunkedBean" writer="MSmpTestChunkedBean"/>
</tasklet>
</step>
</job>
<bean id="AsyncMSmpTestChunkedBean" parent="AsyncItem">
<property name="processor" ref="MSmpTestChunkedBean"/> <!-- ItemProcessor Bean 설정 -->
<property name="size" value="5"/> <!-- Thread 개수 -->
</bean>