SQL ID
DBIO 편집기의 SQL ID 페이지에 대해 설명합니다.
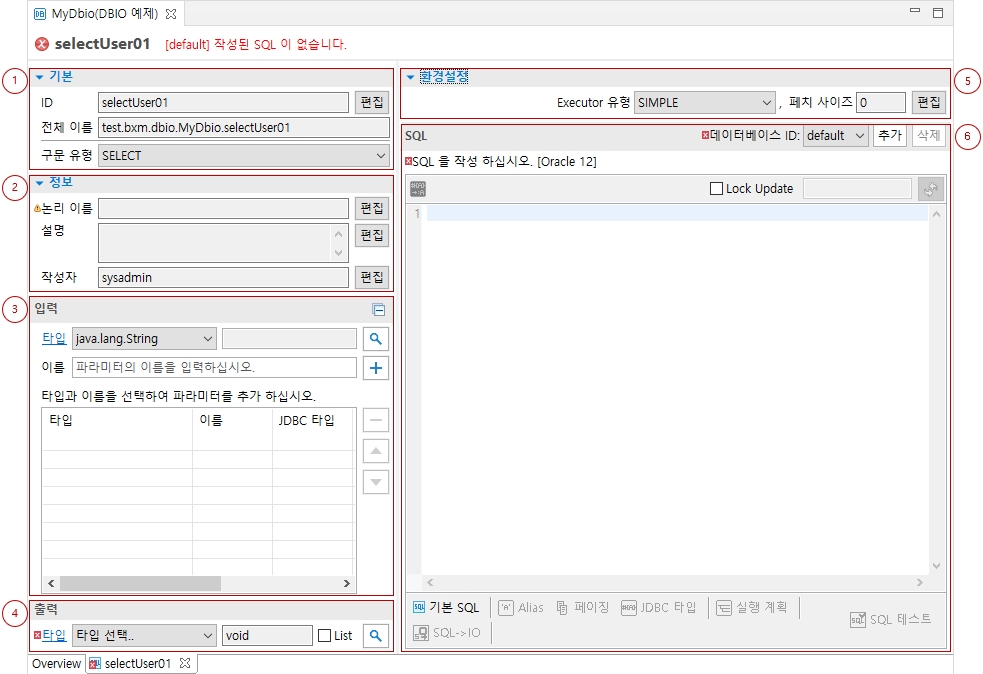
-
기본: 기본 정보를 확인할 수 있습니다.
-
정보: 논리 이름과 설명등의 정보를 확인할 수 있습니다.
-
입력: SQL ID 의 입력 타입을 지정할 수 있습니다.
-
출력: SQL ID 의 출력 타입을 지정할 수 있습니다.
-
환경설정: SQL ID 의 기타 옵션을 설정할 수 있습니다.
-
SQL: SQL 을 작성할 수 있습니다.
1. 기본
기본 정보를 확인할 수 있습니다.
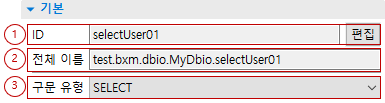
-
ID: SQL ID 의 ID 를 편집할 수 있습니다.
-
전체 이름: Mapper 의 전체 이름과 SQL ID 의 ID 를 확인할 수 있습니다.
-
구문 유형: 구문 유형을 선택할 수 있습니다. 선택할 수 있는 구문 유형은 다음과 같습니다.
-
SELECT -
INSERT -
UPDATE -
DELETE -
MERGE
-
2. 정보
논리 이름과 설명 등의 정보를 확인할 수 있습니다.
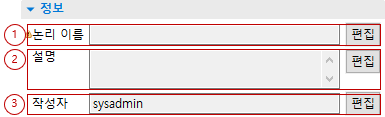
-
논리 이름: DBIO 의 논리 이름을 편집할 수 있습니다.
-
설명: DBIO 의 설명을 편집할 수 있습니다.
-
작성자: DBIO 의 작성자를 편집할 수 있습니다.
3. 입력
SQL ID의 입력 타입을 지정할 수 있습니다.
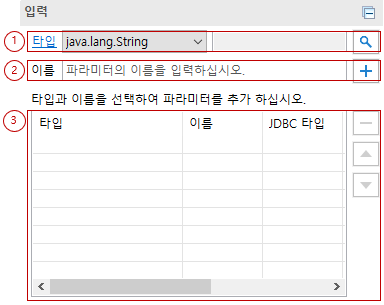
-
타입: 사용할 타입을 검색할 수 있습니다.
-
이름: 파라미터의 이름을 입력 할 수 있습니다. 파라미터가 여러 개인 경우에는 파라미터 이름은 필수로 입력해야 합니다.
-
파라미터: 파라미터 목록을 확인할 수 있습니다.

5. 환경설정
SQL ID의 기타 옵션을 설정할 수 있습니다.

5.1. Executor 유형
Executor 유형을 지정합니다.
DBIO의 결과는 List로 한번에 받아 오게 됩니다. 대량 데이터를 처리하는 배치에서는 처리 성능 및 시스템의 메모리 등의 리소스를 효율적으로 사용하기 위해서 레코드를 일정한 개수씩 반복적으로 조회하여 처리해야 합니다. 이 경우 Excutor 유형을 CONNECTED_BATCH로 설정하면 레코드를 일정한 개수씩 반복적으로 가져와 처리할 수 있습니다.
-
SIMPLE
일반적으로 사용하는 유형 입니다.
-
SELECT: 복수의 레코드가 조회된 경우, 처리 결과를 한 번에 List에 담아서 반환합니다.
-
INSERT/UPDATE/DELETE: 쿼리 요청 단위로 처리합니다.
-
-
CONNECTED_BATCH
일반적으로 배치 작업 같이 대량의 데이터 처리 및 조회를 하는 작업에서 사용되는 유형 입니다.
-
SELECT: 대량의 데이터 조회 시 모든 데이터를 한 번에 가져오는 것이 아니라 Fetch Size 만큼의 데이터를 가져와 처리하고 요청하면 다음 레코드를 가져오는 방법입니다.
-
INSERT/UPDATE/DELETE: 쿼리가 수행 되었을 때 요청 단위로 addBatch를 수행하고 트랜잭션이 종료되거나 세션이 반환될 때 updateBatch로 DBMS 에 한 번에 반영합니다.
-
6. SQL
SQL을 작성할 수 있습니다.
6.2. 옵션
-
Lock Update: 구문 유형이
SELECT일 때 활성화됩니다.데이터의 업데이트를 목적으로 특정 레코드를 조회할 경우에 조회한 시점의 조회 조건과 업데이트 시점의 조건이 다르게 되면 데이터의 정합성에 문제가 발생할 수 있습니다. Lock Update SQL 기능은 선택된 행들에 대하여 배타적인 LOCK 을 설정할 수 있는 기능을 제공합니다. Lock Update 는 다음 상황에서 활용할 수 있습니다.
-
특정 데이터에 대해 동시 트랜잭션이 발생하여 데이터 정합성이 깨지는 것을 방지하고자 할 경우
-
업데이트 처리 진행 중인 데이터를 다른 세션에서 읽는 것을 방지하고자 하는 경우
-
-
Before Image: 구문 유형이
UPDATE/DELETE일 때 활성화됩니다.감사 등의 사유로 데이터의 변경에 대해 기록이 필요한 중요 원장 테이블의 데이터를 변경하는 SQL에 해당 설정을 적용하면 프레임워크에서 변경 전후의 데이터를 자동으로 남기게 됩니다. 해당 기능은 SQL 수행 시 변경 전/후 데이터를 조회하여 프레임워크의 특정 테이블에 남기게 됩니다. 사용자가 작성한 SQL과 별개로 추가적인 처리를 위한 SQL을 수행합니다. 따라서, 남용되어 사용되는 경우 SQL 처리 성능 및 변경 전/후 데이터가 과다하게 쌓이는 등 비효율성이 발생할 수 있으므로 선별해서 사용해야 합니다.
6.4. 도구모음
SQL 작성하는데 도움을 줄 수 있는 도구를 사용할 수 있습니다.
-
기본 SQL: 테이블을 선택하여 선택한 구문 유형에 맞는 SQL 을 생성할 수 있습니다.
-
Alias: 작성된 SQL의 컬럼에 alias 가 없는 경우 alias를 붙여 줍니다.
-
페이징: 페이징 처리를 위한 SQL 을 작성된 SQL 의 앞뒤에 추가해 줍니다.
구문 유형이
SELECT이고 출력 타입에 List 항목이 체크 되어 있어야 사용할 수 있습니다. -
JDBC 타입: 작성된 SQL에 포함된 mybatis 바인딩 변수에 JDBC Type 을 일괄 적용/해제 할 수 있습니다.
SQL의 바인딩 변수에
null값을 전달하기 위해서는 각 변수마다#{feduEmpNm, jdbcType=VARCHAR}과 같이 JDBC Type 을 명시해야 합니다. 이러한 JDBC Type을 일괄 적용/해제 할 수 있습니다. -
실행 계획: 작성한 SQL 의 실행 계획을 확인할 수 있습니다.
-
SQL→IO: 작성한 SQL 의 실행 결과로 입출력 IO 를 생성할 수 있습니다.
-
SQL 테스트: 작성한 SQL 을 실행하고 결과를 확인할 수 있습니다.